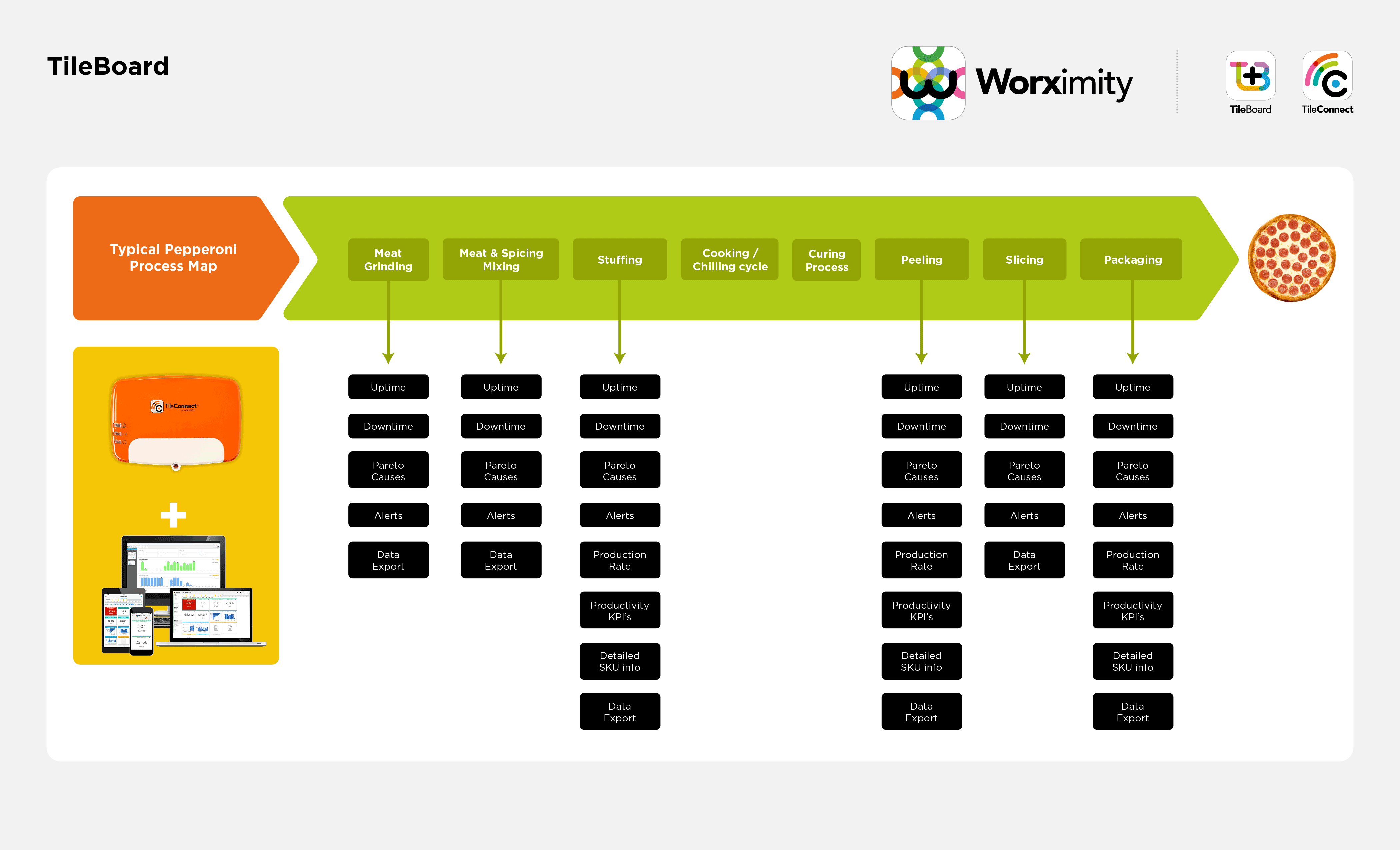
.png)
Combattre les temps d’arrêt est une tâche sans fin pour beaucoup d’industries. Ils grugent les marges et la réputation, ce qui les rend incroyablement dangereux. Pire : ils peuvent survenir fréquemment et passer inaperçus. L’ISA a constaté que beaucoup d’entreprises sous-estiment leur coût total de temps d’arrêt de 200 à 300 %, ce qui signifie qu’elles ignorent largement les dégâts subis. La seule façon d’éliminer le coût des temps d’arrêt est d’abord d’identifier où et quand ils se produisent. Le suivi est donc vital pour qui veut améliorer son résultat net.
Suivre les temps d’arrêt
Le suivi peut se faire de plusieurs façons : automatique ou manuel. Le manuel a des défauts importants : les humains sont moins précis que les machines et peuvent avoir des incitatifs à mal rapporter.
Suivi manuel
Quand le suivi est fait par les employés, c’est souvent à la main ou sur tableur. En théorie, l’opérateur note la durée de l’arrêt, la raison, la machine ou la partie du système touchée, et d’autres détails. Mais les problèmes sont multiples. Le plus évident : les données manuscrites peuvent être perdues, mal classées ou supprimées par erreur — même sur ordinateur. La saisie manuelle rend aussi l’accès aux données difficile pour les bonnes personnes. Les données en tableur sont difficiles à exploiter pour générer des insights actionnables.
D’autres problèmes viennent de la saisie : données inexactes. L’opérateur peut estimer la durée, ou pire, ne pas noter les courts arrêts. Si les estimations sont sous-évaluées ou les micro-arrêts négligés, le temps cumulé coûte cher sans être documenté.
Les employés peuvent aussi se sentir pressés de reprendre le travail et ne pas noter assez de détails sur l’origine ou la cause. Sans cause, pas de correction. Et il y a la possibilité de saisies inexactes volontaires pour masquer des périodes d’arrêt excessif — par paresse ou stress.
Suivi automatisé
Le suivi automatisé règle beaucoup de problèmes d’erreur humaine. Il libère les employés qui peuvent se concentrer sur l’opération, et documente les arrêts plus précisément.
Le plus d’informations possibles est nécessaire pour identifier exactement la cause d’un arrêt — facile pour un système automatisé. Détails utiles : zone de procédé, machine, produit en cours, numéro de quart, heure. Pannes machines, difficultés sur certains produits et travail bâclé peuvent tous être révélés. Mieux : ces détails peuvent être saisis à l’avance et suivis automatiquement — info produit à chaque démarrage, heure réglée une fois, quart selon l’horaire, machine et zone selon la station.
Le détail le plus important reste la cause, parfois collectée automatiquement via un code d’erreur machine ou une mesure précise entre machines interconnectées. D’autres fois, l’opérateur doit la saisir — ce qui réintroduit de l’erreur humaine. S’il se sent pressé, il peut saisir une cause inexacte.
Pour éviter cela, le logiciel doit être aussi simple que possible. Une liste de causes raisonnable : ni trop courte (pour éviter « autre » en tête), ni trop longue (pour rester rapide à parcourir). Un champ « commentaires opérateur » est utile pour ajouter des détails. Si l’opérateur travaille fréquemment sur la machine en panne, qui mieux que lui sait ce qui a cloché ?
Diagrammes de Pareto
Une fois les données collectées, un Pareto révèle les principales causes. Vilfredo Pareto a énoncé la règle des 80-20 : 80 % des effets viennent de 20 % des causes. Souvent, peu de problèmes causent la majorité des temps d’arrêt. Le Pareto classe les arrêts pour identifier la cause principale. Cela nécessite la précision qu’apporte le suivi automatisé, pour que même les petits arrêts puissent être améliorés ou éliminés s’ils causent des problèmes significatifs.